决策树
概念
(decision tree),是一种基本的分类与回归方法。分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点(node)和有向边(directed edge)组成。结点有两种类型:内部结点(internal node)和叶结点(leaf node)。内部结点表示一个特征或属性,叶结点表示一个类。
把决策树看成一个if-then规则的集合,将决策树转换成if-then规则的过程是这样的:由决策树的根结点(root node)到叶结点(leaf node)的每一条路径构建一条规则;路径上内部结点的特征对应着规则的条件,而叶结点的类对应着规则的结论。决策树的路径或其对应的if-then规则集合具有一个重要的性质:互斥并且完备。这就是说,每一个实例都被一条路径或一条规则所覆盖,而且只被一条路径或一条规则所覆盖。
##准备工作
- 特征选择
选择标准:信息增益(information gain)或信息增益比- (香农)熵:信息期望值
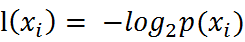
- 所有类别所有可能值包含的信息期望值(数学期望):
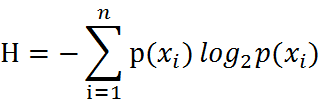
- (香农)熵:信息期望值
- 经验熵:概率由数据估计(最大拟然估计)得到
- 条件熵
- 决策树生成和修改
数据集构造决策树算法所需要的子功能模块,包括经验熵的计算和最优特征的选择。其工作原理如下:得到原始数据集,然后基于最好的属性值划分数据集,由于特征值可能多于两个,因此可能存在大于两个分支的数据集划分。第一次划分之后,数据集被向下传递到树的分支的下一个结点。在这个结点上,我们可以再次划分数据。因此我们可以采用递归的原则处理数据集。
构建决策树的算法有很多,比如C4.5、ID3和CART,这些算法在运行时并不总是在每次划分数据分组时都会消耗特征。由于特征数目并不是每次划分数据分组时都减少,因此这些算法在实际使用时可能引起一定的问题